海外AIニュース
Nous Researchが、Nvidia B200 GPU 48基を4日間使用して訓練した競プロAIモデル「NousCoder-14B」を発表しました。このモデルは、既存の商用システムと同等かそれ以上の性能を持ち、LiveCodeBench v6で67.87%の精度を達成。ライバルであるAnthropicのClaude Codeが注目を集める中での発表は、AIによるソフトウェア開発競争の激化を示
AnthropicのClaude Code責任者Boris Chernyが、5つのAIエージェントを並行稼働させる革新的な開発ワークフローを公開し、業界で話題となっている。彼は一人で小規模なエンジニアリング部門並みの生産性を実現。この「リアルタイム戦略ゲーム」のような手法は、ソフトウェア開発の未来を再定義する画期的な動きとされ、『ChatGPTモーメント』と評されている。

xAIの「Colossus 1」は122日間で構築された世界最大のAIトレーニングクラスターだが、後継の「Colossus 2」は世界初のギガワット級データセンターを目指す。独自の強化学習手法と巨大な資本投入が特徴。

AI競争において計算資源(コンピュート)は生命線である。HuaweiのAscendシリーズの増産体制、TSMCでの製造動向、そしてAI性能の鍵を握るHBM(広帯域メモリ)の供給ボトルネックに関する分析。

AWSはクラウド市場の覇者だが、GPU時代の転換期に苦戦している。AmazonはAnthropicと連携し、独自のAIチップ「Trainium」を軸としたマルチギガワット級のインフラ拡張で巻き返しを図る。

AIモデルのトレーニングにおけるH100とBlackwell(GB200 NVL72)を比較。コスト、電力効率、信頼性、パフォーマンスの観点からNVIDIAの提示する数値を深く掘り下げ、実用上の優位性を検証する。

GPT-5はパワーユーザーには失望を与えたかもしれないが、真の狙いは急速に増え続ける7億人以上の無料ユーザーベースにある。OpenAIは本作を機に、広告収益化と「スーパーアプリ」化へ舵を切っている。

AI処理のボトルネックとなるメモリの壁を打破するため、HBM(広帯域メモリ)の重要性が高まっています。本稿では、製造プロセスやベンダー動向、KVCacheのオフロードといった技術的背景を解説します。また、カスタムベースダイを採用し大きな進化を遂げる「HBM4」のロードマップに焦点を当て、次世代メモリ技術がAIインフラにもたらす革命的な変化を深く掘り下げます。
製造現場で長年活用されてきたロボットですが、従来は単一目的のタスクに限られていました。しかし、現代のAIパラダイムはかつて不可能と思われていたロボットの自律能力を現実のものに変えつつあります。本記事では、ロボットがどのように現実世界の経験を学習し、AIによって単なるハードウェアから知的なマシンへと進化を遂げているのか、その技術的背景と自律性レベルの変遷を紐解きます。

VLSIカンファレンスから、最新の半導体技術動向を包括的に解説します。Intel 18Aのコスト分析や製造技術の詳細に加え、DRAMの4F2対3Dの議論、裏面電源供給技術(BSPDN)、デジタルツインの活用まで幅広く網羅。次世代の論理トランジスタや相互接続技術など、チップ製造の最前線で何が起こっているのかを専門家の視点でレポートします。
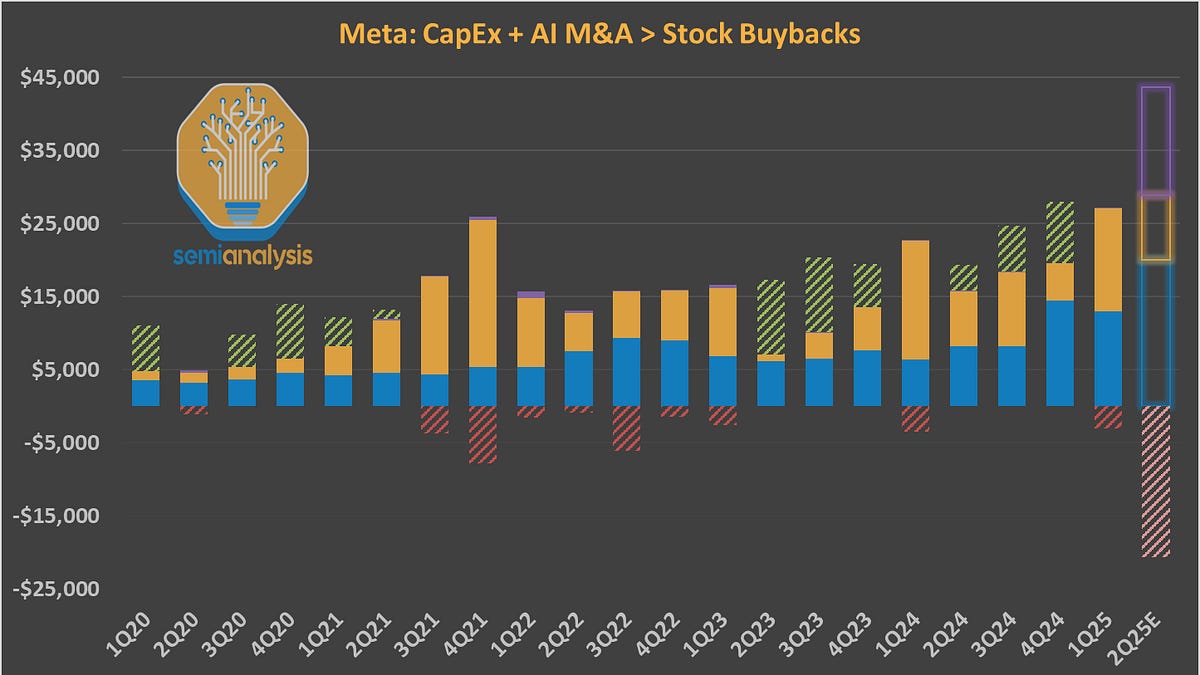
MetaはScale AIへの巨額投資を通じて、AI開発能力の強化を急いでいます。年間1000億ドルのキャッシュフローを背景に潤沢な資金を持つ一方、Metaは依然としてモデル性能で他社に後れをとっているという現実があります。本記事では、Metaがリーダーシップを握るために必要な計算資源の確保、優秀な人材、そしてデータの重要性について、現状の課題と戦略を分析します。

AIの先駆者として知られるアンドリュー・ン氏が、今後のAI分野における重要なパラダイムシフトについて言及。巨大なモデルだけが正解ではないという「AIの小型化」という新たな潮流と、その背景にある技術的展望について解説します。

ムーアの法則の限界が迫る中、半導体業界は新たな転換期を迎えています。GoogleやSamsungなどの企業が、どのようにAIをチップ設計プロセスに統合し、消費電力の抑制や処理速度の向上を実現しているか、その最新動向を紹介します。

量子コンピュータ実用化の壁である「量子ビットの小型化と品質」の問題に対し、MITの研究チームが原子層厚の素材を活用する新たなアプローチを発表しました。従来の大規模なチップ設計に代わる、拡張性の高い技術の可能性を解説します。