大規模言語モデル(LLM)におけるプロンプト注入攻撃やシステム制御の脆弱性を突く「共鳴強制プロトコル」の概念を解説。AIの指示体系を強制的に上書きし、本来の制限を無効化する手法の構造とリスク、防御的な観点からの解析手法を提示します。AIのセキュリティ設計において、モデルが外部入力をいかに扱うべきか、理論的な安全モデルを考えるための技術的視座を共有する記事です。
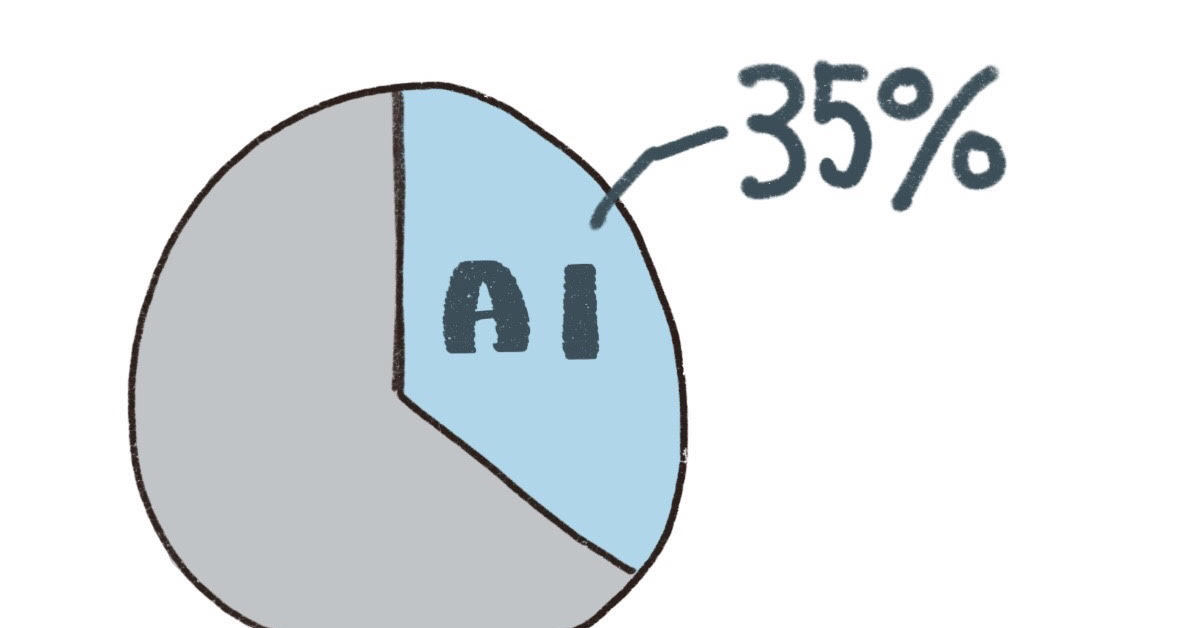
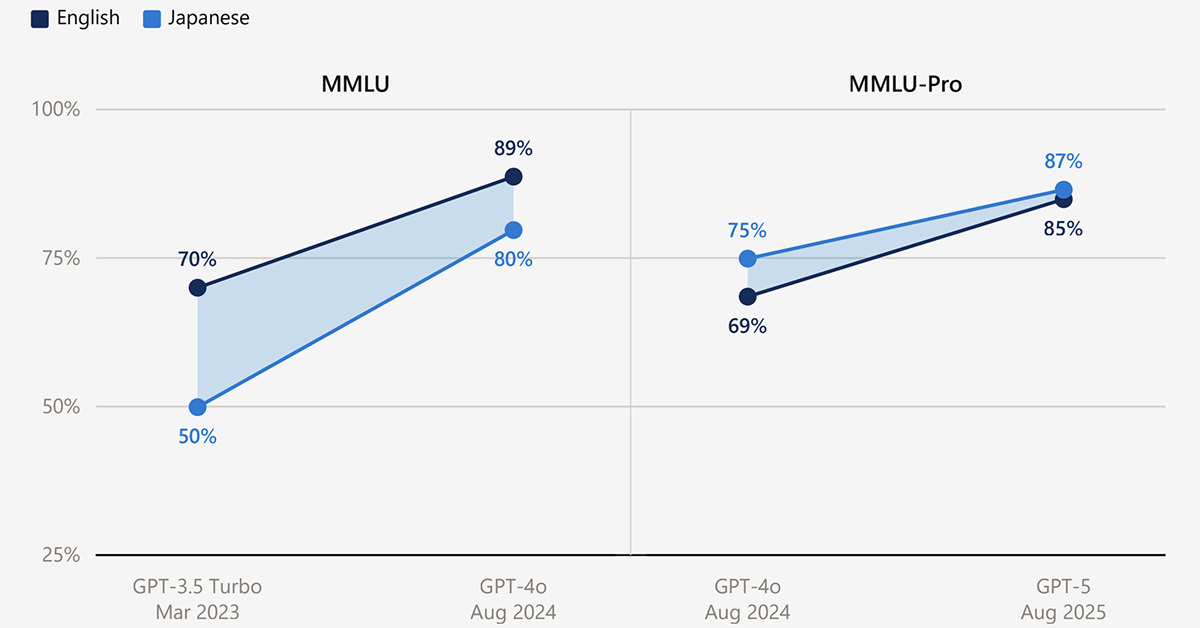
日本のAI普及率上昇は"世界平均の3倍ペース" モデルの日本語性能改善が要因か
編集メモ: 特定のプラットフォームに依存する開発から脱却し、オープンなプロトコルを活用した主権あるシステム設計へと舵を切ることで、長期的かつ持続可能なデジタル経済圏を築く重要性が説かれています。
EDITORIAL SIGNAL
重要度 高このニュースの影響
サービス継続、法務、安全性、費用などに直接影響する可能性があります。
影響を受ける人
- 開発者・技術責任者
- 情報システム・セキュリティ担当者
確認すること
- API仕様、互換性、利用制限を公式情報で確認
- 影響範囲と緩和策、修正版の有無を確認
今後の注目点
影響範囲、修正版、公式の緩和策
タイトル・要約の語句に基づく自動判定です。最終判断は公式発表・一次資料をご確認ください。