Qwen / Alibabaの最新ニュースまとめ
このページでわかること
- Qwen / Alibaba 関連の国内・海外の直近ニュース 56 件を集約
- 最新から時系列順に並び、難易度バッジ付きで読みたいレベルを選べる
- 国内メディア(ITmedia / AINOW / GIGAZINE 等)と海外メディア(TechCrunch / The Verge 等)を横断
- 毎時自動更新、Gemini による日本語要約とCTR最適化済タイトル
Alibaba の Qwen シリーズなどオープンモデル最新動向
56件の記事

家庭用GPU(RTX 4070)で35Bクラスのモデルを高速化する手法を解説。`--cpu-moe`などのフラグ活用により速度を2.8倍に引き上げる実測データや、品質検証の手法を全10章で構成。

Anthropicは、中国Alibabaが2万5000以上の偽アカウントを使い、2880万回以上のアクセスを通じて自社の「Claude」モデルを不正に蒸留(学習)したと主張している。違反は2026年4月から6月にかけて発生したとされる。
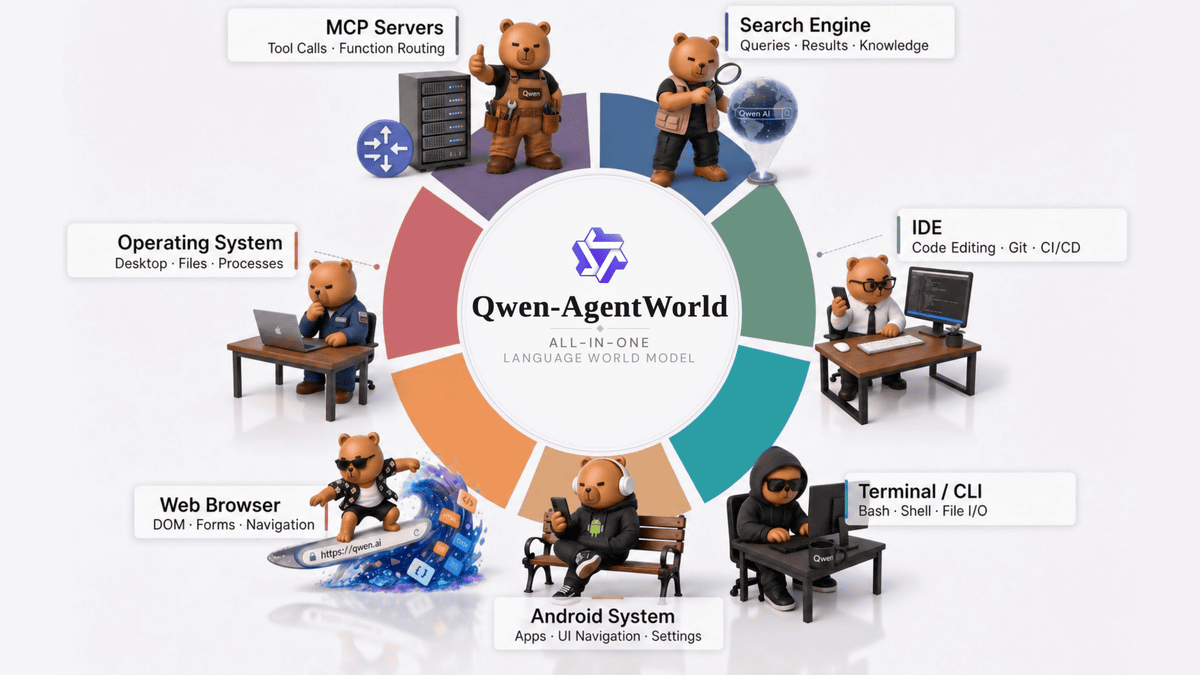
AlibabaのAI研究チームQwenは、2026年6月23日に「Qwen-AgentWorld」を公開した。言語モデルに基づく世界モデルであり、汎用エージェント能力を向上させる新たなアプローチとして注目されている。

Anthropicが、中国AlibabaのAI研究機関による「蒸留攻撃」をホワイトハウス等に告発した。AIモデルの技術流出に関する深刻な懸念が示されている。

商用利用可能な多言語対応Voice Clone OSSが3つ出揃った。Mac環境で動作するQwen3-TTS、CosyVoice 2などを紹介し、それぞれの特徴や性能、導入時の注意点を整理して解説する。

Gemma 4の各モデル(12B, E4B, 26B等)をRTX 4070(VRAM 12GB)で検証。速度、VRAM消費、正解性をクラウドモデルの基準で実測比較した検証レポート。

AlibabaのAIチームQwenが、2026年6月16日にロボット開発用AIモデル群「Qwen-Robot Suite」を発表した。ターゲット追跡や自動運転向けの「RobotNav」、アーム操作の「RobotManip」、世界認識を行う「RobotWorld」の3モデルで構成されている。


RTX 5090とWSL UbuntuでQwen3.6-27B-MTP-GGUFを動かす環境構築の続編。前回のDockerベースのOpenAI互換API構築に加え、今回はLiteLLM Proを用いた構成変更について解説する。

米国防総省は2026年6月8日、中国の人民解放軍を支援しているとして、Alibaba、Baidu、BYDなどの中国企業を「1260H条リスト」と呼ばれるブラックリストに追加した。

AIによる自動コードレビューでの課題であるチェック漏れや品質のばらつきを解決するため、Alibabaが開発した「Open Code Review」を紹介。数万人の開発者が利用し、すでに100万件の欠陥を検出している実用性の高いツールです。

DGX Spark環境でSGLangとQwen3.6-35Bモデルを動かす構成。自作ゲートウェイからLiteLLM Proxyへの移行により、OpenAI互換APIをより安定して構築する手順と背景を解説。

アリババグループがAIモデル「Qwen」のAIエージェント機能を第三者に開放すると発表。ユーザーはアプリを通じてKFCやラッキンコーヒーなどの注文が可能になります。

AlibabaのQwen3.6-35B-A3Bを32GBメモリのMac環境で検証。実用性、速度、メモリ使用量を公開し、日常運用における現実的な評価をまとめる。

Mac Mini M4環境でローカルLLMサーバーを構築し、認証やリクエスト制限を含むゲートウェイをPythonで自作して安全にLAN公開する方法。

AlibabaのAIチームQwenが「Qwen3.7-Plus」を発表。ベンチマークテストの一部ではClaude Opus4.6を上回る性能を記録し、高い注目を集めています。

ChatGPT o3-pro、Claude 4 Opus、Gemini 2.5 pro、Qwen3 235Bの4つの最新AIモデルに「ドーナツのジョーク」を依頼。モデルごとのユーモアのセンスや回答の特徴を比較検証しています。

Qwenチームが公開したGSPO(Group Sequence Policy Optimization)を解説。推論モデルの強化学習で発生する「長時間学習によるモデル破壊」という根本課題に挑む最新技術を深掘りする。

DGX Spark環境でQwen3.6-35B-A3B-FP8モデルをSGLangで動かす手法。AIエージェント開発に最適なMoEモデルの選定から、効率的な推論APIサーバーの構築手順を技術的に解説します。

コーディング用途に特化したローカルLLMの性能をベンチマークで測定。DeepSeek V4 FlashやQwen3.6 35Bなどを対象に、量子化モデルでの推論精度や速度をAider Polyglotのサブセットで比較検証。

Jetson AGX XavierでQwen3.6を動作させる試み。Jetpack 5のサポート終了という制約の中、OrinとRAM容量が同じ32GBのXavierで有終の美を飾るべくモデルを実行するための技術的背景や注意点を記録する。

Windows 11およびRTX 5090環境で、Qwen3.6-27B LLMを構築する手順を公開。128Kの長コンテキスト処理を実現するための、llama.cpp serverを用いた推論基盤構築と高速化手法について解説する。

OrcaRouterがAlibaba Qwen 3.7 Max APIのサポートを開始しました。エンタープライズ向けのマルチモデルゲートウェイ機能が強化されています。

Qwen 3.7の現状を整理し、ローカルLLMにおける情報の追い方と評価指標の読み方を解説。公開情報に基づいたQwenモデルの現状と、ベンチマークを正しく解釈するためのガイドラインを提示。

Alibabaは新しい自社製AIアクセラレータを公開しましたが、生産規模は限られています。先行する競合他社に追随する難しさを露呈しており、AI分野でのハードウェア開発における苦境が浮き彫りとなっています。

AlibabaのQwenチームがAIエージェント向けの新基盤モデル「Qwen3.7-Max」を発表。チャット型を超え、複雑な業務を自動化するエージェント時代に特化した設計が特徴。
Ollama v0.30系プレリリースの変更点を解説。llama.cppの直統合による推論高速化やGGUFの完全サポート、メモリ管理の改善により、Apple Silicon環境などでさらなるパフォーマンス向上が期待できます。

ロシアのSberbankは、欧米の制裁下で自社のAI「GigaChat」を強化するため、中国製チップの調達を検討しています。最有力候補はHuaweiの「Ascend 950」と見られますが、ByteDanceやAlibabaといった中国国内の巨大IT企業が優先されるため、供給獲得までには長い待ち時間が発生する見通しです。

AlibabaがAIエージェントに特化した新プロセッサ「Zhenwu M890」を発表。単なるチップ開発にとどまらず、LLMを含めた統合的なAIスタックを構築しており、米国の輸出規制を回避するだけでなく、AIインフラのあり方自体を再定義する戦略を鮮明にしている。

llama.cppのMTP(Multi-Threaded Processing)対応PRがマージされたことを受け、ハイエンド環境(RTX 4090/5080等)を用いて実際にどれほど速度向上したかを検証した報告記事。

Codens Purpleのfix_verifyループにおいて、モデルごとの再試行回数を最適化した事例。Claude系は3回、Qwen系は6回、他は5回と個別に設定することで、コストと修正率のバランスを改善した。


VRAM不足でLLMが動かせない問題に対し、llama.cppのRPC機能を用いて2台のPCのGPUをネットワークで束ねる手法を解説。70B級モデルをローカルで動かす試み。

Qwen3、LLM-jp-4、Gemma3の3モデルを物理学の専門知識で比較検証。汎用ベンチマークではなく、専門領域での回答精度と誤り方を赤入れし、実務利用の観点からモデルの特性を深掘りする。

ローカルLLMを動かすために「24GB VRAMが必要」という常識を検証。低スペックGPUでも適切なモデル設定や最適化手法を用いれば、35Bパラメータ級のモデルを実用的に動かせる事例を紹介する。

高性能なPC環境でQwen3.6-35b-a3bをローカル実行し、Webアプリ開発での実用性を評価。AMD Ryzen AI MAX+とRadeon 8060Sを搭載した環境で、ローカルLLMの動作感や開発効率について詳細な検証結果を解説する。


Windows 11環境において、ローカルLLM実行ツール「Ollama」を活用する実験の記録。MCPサーバーの動向とともに、改めてOllamaの活用方法を探求する技術ログ。


Ollamaを用いて3ファミリー6サイズのローカルLLMを比較。ハードウェアスペックを一定に保ち、5つのカテゴリで定量的にベンチマーク測定を行い、用途に応じたモデル選びの判断基準を提供します。

北京モーターショーにて、BYDやフォルクスワーゲンの中国合弁会社が製造する自動車に、Alibabaが開発したAI「Qwen」を搭載することが発表されました。中国市場におけるコネクテッドカーのインテリジェンス化が加速しています。


Claude 3.5 Sonnetの感情ベクトルに関する研究を、Qwen3-4Bを用いてローカル環境で再現する方法を解説。nnsightとGradioを活用した実装コードとともに、モデル内部の感情表現を検証します。

Qwen3.5の構造を理解するためのガイド。Mamba2やSSM(状態空間モデル)の理論的背景を前提に、関連する先行論文や技術ブログを紹介し、Transformerのアテンションとの違いを読み解く。

カスタマーサポートシステムというレッドオーシャン市場で個人開発を続ける理由を考察。市場の需要分析と技術的難易度の観点から、未開拓のチャンスと自身のこだわりを詳述している。

中国AlibabaがオープンなAIモデル「Qwen3.6-27B」を発表しました。一般的なデスクトップ用GPUに搭載可能なサイズながら、高度なコーディング能力を備えている点が大きな特徴です。

AlibabaのAI研究チームQwenが、270億パラメータのマルチモーダルAIモデル「Qwen3.6-27B」を公開しました。Apache License 2.0を採用しており、商用利用が可能なオープンモデルとして提供されます。

最新のQwen3.6-35B-A3Bモデルを実機検証した記録。RTX 5090環境下で当初想定より遅い18 t/sという結果が出た原因を突き止め、最適化プロセスを報告します。

Claude Codeを用いた自律システムの運用コストを大幅削減する方法を紹介。タスクのルーティング設計により、安価なローカルモデルと高精度なOpusを使い分けることで、月額費用を108ドルから3.6ドルまで削減した実例と技術構成を解説します。

ローカルOllamaとClaude Codeの組み合わせで動作が不安定になる原因を6つに分類。OSSの「CodeRouter」を活用した再現性の低いエラーを実地で検出・特定する方法を解説する。