Google Researchが発表した大規模言語モデル向け圧縮技術「TurboQuant」の解説サイトが公開されました。AIモデルのメモリ消費を抑えつつ、検索性能と処理速度を向上させるこの技術の仕組みを、視覚的に理解できるよう解説されています。
AIを数分の1のデータ量で動かすための「TurboQuant」の仕組みをインタラクティブな図解で把握できるサイト「TurboQuant: A First-Principles Walkthrough」
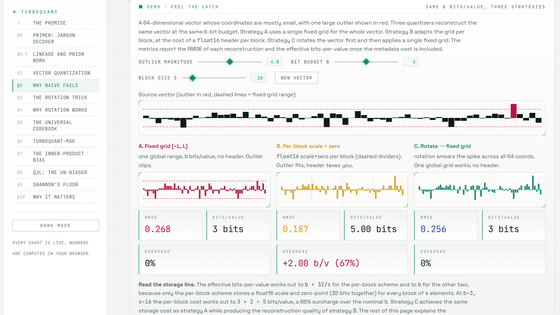
編集メモ: Googleが発表したAI圧縮技術「TurboQuant」の解説サイトにより、モデルの軽量化と高速化を両立させる最先端の知見を、図解を通じて効率的に習得できます。